Unique Experiences
Recent AI innovations created by our team:
- “Improved Deep Learning by Inverse Square Root Linear Units (ISRLUs)”
- ICLR 2018 conference submission & arXiv posting, Tensorflow, MXNet, & Gluon
- ISRLU can improve accuracy & performance on CNNs, GANs, & CapsuleNet (Hinton, et al)
- “Columnar In-memory Database Techniques for Creating AI and ML Features”
- VLDV 2018 conference submission & arXiv posting
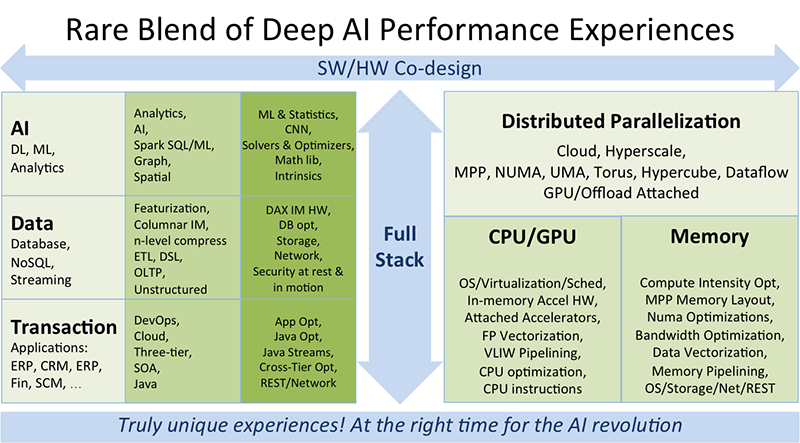
Below is a list of the wide variety of our unique performance engineering experiences that inform our AI performance Tuning!
Architecture
- Enterprise Architecture
- Processor Architecture
- HW Accelerator Architecture
- Server Architecture
- System Architecture
Analytics Apps (Full-stack optimization)
- Spark ML (training/scoring asymmetry), BLAS3 opt
- Oracle Adv Analytics (training/scoring asymmetry)
- Oracle PGX Graph
- TensorFlow
- SAS, SPSS, FPSMath(made public ‘89)
- Homegrown statistics packages
- Oracle Spatial
- TensorFlow, MXNet, Gluon, Numpy, R, Python, matplotlib, ...
Transactional Apps (Full-stack optimization)
- Fusion Apps(Java)
- SOA
- Oracle E-Business, SAP, Peoplesoft, Siebel, JD Edwards, Fusion Apps, Manugistics, Baan…
Data Management
- ETL for ML, BigData SQL, SAS ETL, Informatica ETL,
- Spark SQL
- Columnar In-memory: Oracle, SybaseIQ, Expressway,
- Oracle NoSQL, Cassandra NoSQL, key-value
- Oracle DB, MySQL, DB2, ...
- Data Warehousing, Datamarts, In-memory Aggregation
- Kafka Streaming
Java/JVM/GC
- Java Streams (HW DAX)
- REST (Jersey, Grizzly)
- Intrinsics - inline assembly accelerators
Cross-stack examples
- Moving DB functions to Disk controllers
- Hybrid Columnar Compression
MPP/Cloud
- Oracle Cloud, MPP, 3D torus, Vector Hypercube, Dataflow machine, …
- Storage, Network, Compute optimization
- Matrix co-processor
- Attached Processors (GPU)
Parallel Performance
- Near-linear Scaling (MPP, NUMA, SMP), major restructuring algorithms for parallel
- Modeling/estimation
- Instrumentation (w/ myriad of tools)
- Analysis(Shortfall), Rectification
- OS: sched, thread tuning, lock splitting
CPU
- VLIW SW pipelining
- RISC/CISC optimization: RAW, etc
- Vectorization
- SPARC, x86, i860, Cray YMP, FPS-VLIW, FPS XP-32,Transputer, systolic arrays,…
- In-memory accelerations (DAX,…)
HPC
- Financial Derivatives
- Signal processing, Beam-forming ,…
- Structural Analysis
- Computation Chemistry
- Physics (CFD, MHD, QCD, QED,..)
- EDA
- Seismic Oil/Gas
- Gov
- Ad Hoc Customer
- MPI
- OpenMP
- OpenCL
- InfiniBand, Ethernet Clusters
Math Library
- Solvers, Eigen, mixed-radix FFT, Derivative, Seismic, conv/deconv, linear prog, conjugate gradient, Strassen matmul, Winograd, compression, simulation, signal processing…
- Out-of-Core equation solvers
- BLAS3,2,1
- Intrinsics (various precision)
- Automatic Differentiation & nonlinear solvers
- High-accuracy long accumulator solvers
- Interval Math
Memory
- Compute intensity optimization
- Data vectorization
- BW, bisection BW
Network
- REST (Jersey, Grizzly)
- small-packet optimization
- Large-packet optimization
- Structured Asynch Pipelined for MPPs
- Interrupt tuning/scalability
- IB, various network techm
- Storage optimization, Filesystem, QFS,…
Security/Crypto
- Security Kernels
- Secure Network
- Secure Filesystem
- Oracle TDE
- Oracle Data Redaction
- SSM (Silicon Secured Memory)
Virtualization
- LDoms, Zones,
- Optimized Virtualized Storage, Network, & CPU